用AI作了一个网页采集和AI处理系统
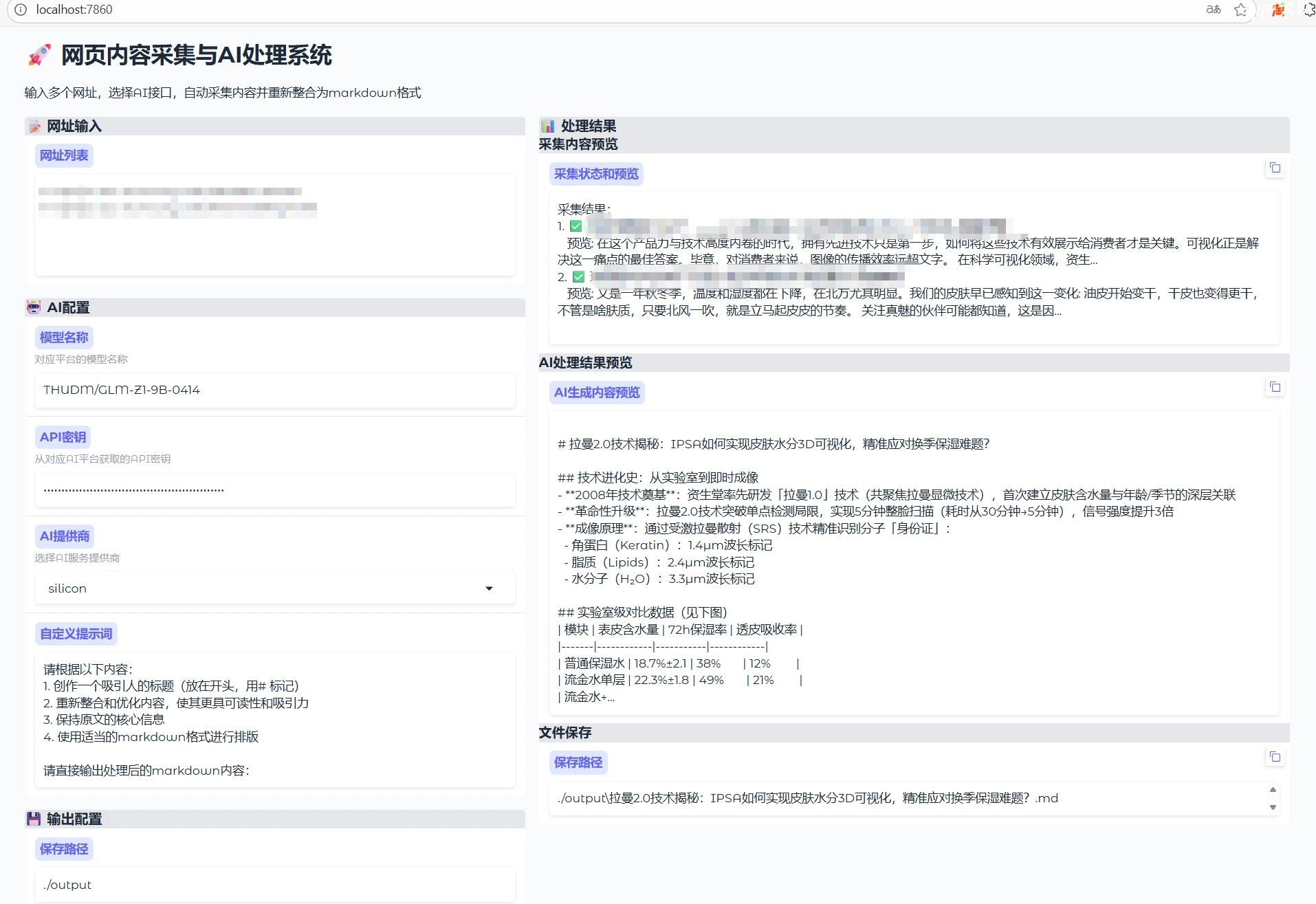
main.py
import gradio as gr
import requests
from bs4 import BeautifulSoup
import json
import os
import re
from datetime import datetime
import markdown
import time
import random
from typing import List, Dict, Optional
class ContentCollector:
def __init__(self):
self.session = requests.Session()
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
})
def extract_content(self, url: str) -> Dict:
"""从URL提取内容"""
try:
response = self.session.get(url, timeout=10)
response.encoding = response.apparent_encoding
soup = BeautifulSoup(response.text, 'html.parser')
# 提取标题
title = soup.find('title')
title_text = title.get_text().strip() if title else "无标题"
# 提取主要内容
content_selectors = [
'article',
'main',
'.content',
'.article-content',
'.post-content',
'#content'
]
content = ""
for selector in content_selectors:
element = soup.select_one(selector)
if element:
content = element.get_text().strip()
break
# 如果没有找到主要内容,使用body
if not content:
body = soup.find('body')
if body:
# 移除脚本和样式
for script in body(["script", "style"]):
script.decompose()
content = body.get_text().strip()
# 清理内容
content = re.sub(r'\s+', ' ', content)
return {
'url': url,
'title': title_text,
'content': content[:5000], # 限制内容长度
'success': True
}
except Exception as e:
return {
'url': url,
'title': f"采集失败: {str(e)}",
'content': "",
'success': False
}
class AIClient:
def __init__(self):
self.timeout = 30
self.max_retries = 3
self.retry_delay = 2
def _make_request_with_retry(self, url: str, headers: dict, data: dict, provider: str) -> Dict:
"""带重试机制的请求函数"""
last_exception = None
for attempt in range(self.max_retries):
try:
print(f"🔗 [{provider}] 第 {attempt + 1} 次尝试请求...")
response = requests.post(
url,
headers=headers,
json=data,
timeout=self.timeout
)
response.raise_for_status()
return {
'success': True,
'data': response.json()
}
except requests.exceptions.Timeout as e:
last_exception = f"请求超时 (尝试 {attempt + 1}/{self.max_retries})"
print(f"⚠️ {last_exception}")
except requests.exceptions.ConnectionError as e:
last_exception = f"连接错误 (尝试 {attempt + 1}/{self.max_retries}): {str(e)}"
print(f"⚠️ {last_exception}")
except requests.exceptions.HTTPError as e:
if hasattr(e, 'response') and e.response is not None:
status_code = e.response.status_code
if status_code == 401:
return {
'success': False,
'error': f"API密钥无效或权限不足 (HTTP 401)"
}
elif status_code == 429:
return {
'success': False,
'error': f"请求频率过高,请稍后重试 (HTTP 429)"
}
elif status_code == 403:
return {
'success': False,
'error': f"访问被拒绝,请检查API密钥和权限 (HTTP 403)"
}
elif status_code == 400:
# 尝试从响应中获取更详细的错误信息
try:
error_detail = e.response.json().get('error', {}).get('message', '请求参数错误')
except:
error_detail = '请求参数错误'
return {
'success': False,
'error': f"请求错误: {error_detail} (HTTP 400)"
}
else:
last_exception = f"HTTP错误 (尝试 {attempt + 1}/{self.max_retries}): {status_code} - {str(e)}"
else:
last_exception = f"HTTP错误 (尝试 {attempt + 1}/{self.max_retries}): {str(e)}"
print(f"⚠️ {last_exception}")
except Exception as e:
last_exception = f"请求失败 (尝试 {attempt + 1}/{self.max_retries}): {str(e)}"
print(f"⚠️ {last_exception}")
# 如果不是最后一次尝试,等待后重试
if attempt < self.max_retries - 1:
delay = self.retry_delay * (attempt + 1) + random.uniform(0, 1)
print(f"⏳ 等待 {delay:.1f}秒后重试...")
time.sleep(delay)
return {
'success': False,
'error': f"所有重试均失败: {last_exception}"
}
def call_deepseek(self, content: str, api_key: str, model: str, prompt: str) -> Dict:
"""调用Deepseek API"""
try:
url = "https://api.deepseek.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
# 限制内容长度,避免过长导致超时
truncated_content = content[:3000]
data = {
"model": model,
"messages": [
{
"role": "system",
"content": "你是一个专业的编辑,擅长将内容重新整合并创作吸引人的标题。请用中文回复。"
},
{
"role": "user",
"content": f"{prompt}\n\n原文内容:\n{truncated_content}"
}
],
"temperature": 0.7,
"max_tokens": 2000,
"stream": False
}
print(f"🔗 调用Deepseek API... (内容长度: {len(truncated_content)})")
result = self._make_request_with_retry(url, headers, data, "deepseek")
if result['success']:
response_data = result['data']
return {
'success': True,
'content': response_data['choices'][0]['message']['content'],
'usage': response_data.get('usage', {})
}
else:
return result
except Exception as e:
return {
'success': False,
'error': f"Deepseek API调用异常: {str(e)}"
}
def call_glm(self, content: str, api_key: str, model: str, prompt: str) -> Dict:
"""调用GLM API"""
try:
url = "https://open.bigmodel.cn/api/paas/v4/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
truncated_content = content[:3000]
data = {
"model": model,
"messages": [
{
"role": "system",
"content": "你是一个专业的编辑,擅长将内容重新整合并创作吸引人的标题。请用中文回复。"
},
{
"role": "user",
"content": f"{prompt}\n\n原文内容:\n{truncated_content}"
}
],
"temperature": 0.7,
"max_tokens": 2000
}
print(f"🔗 调用GLM API... (内容长度: {len(truncated_content)})")
result = self._make_request_with_retry(url, headers, data, "glm")
if result['success']:
response_data = result['data']
return {
'success': True,
'content': response_data['choices'][0]['message']['content'],
'usage': response_data.get('usage', {})
}
else:
return result
except Exception as e:
return {
'success': False,
'error': f"GLM API调用异常: {str(e)}"
}
def call_silicon(self, content: str, api_key: str, model: str, prompt: str) -> Dict:
"""调用硅基流动API"""
try:
url = "https://api.siliconflow.cn/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
truncated_content = content[:3000]
data = {
"model": model,
"messages": [
{
"role": "system",
"content": "你是一个专业的编辑,擅长将内容重新整合并创作吸引人的标题。请用中文回复。"
},
{
"role": "user",
"content": f"{prompt}\n\n原文内容:\n{truncated_content}"
}
],
"temperature": 0.7,
"max_tokens": 2000
}
print(f"🔗 调用硅基流动API... (内容长度: {len(truncated_content)})")
result = self._make_request_with_retry(url, headers, data, "silicon")
if result['success']:
response_data = result['data']
return {
'success': True,
'content': response_data['choices'][0]['message']['content'],
'usage': response_data.get('usage', {})
}
else:
return result
except Exception as e:
return {
'success': False,
'error': f"硅基流动API调用异常: {str(e)}"
}
class MarkdownProcessor:
@staticmethod
def save_markdown(content: str, title: str, output_dir: str) -> str:
"""保存为markdown文件"""
# 清理文件名
filename = re.sub(r'[<>:"/\\|?*]', '', title)
filename = filename[:100] # 限制文件名长度
if not filename:
filename = "未命名内容"
filename = f"{filename}.md"
filepath = os.path.join(output_dir, filename)
with open(filepath, 'w', encoding='utf-8') as f:
f.write(content)
return filepath
def check_network_connection():
"""检查网络连接状态"""
test_urls = [
"https://www.baidu.com",
"https://www.qq.com",
"https://api.deepseek.com"
]
for url in test_urls:
try:
response = requests.get(url, timeout=5)
if response.status_code == 200:
return True, f"网络连接正常 ({url})"
except:
continue
return False, "网络连接异常,请检查网络设置"
def validate_api_key(api_key: str, provider: str) -> tuple:
"""验证API密钥格式"""
if not api_key or not api_key.strip():
return False, "API密钥不能为空"
# 移除密钥前后的空格
api_key = api_key.strip()
# 根据不同的提供商进行基本格式验证
if provider == "deepseek":
if not api_key.startswith('sk-'):
return False, "Deepseek密钥应以'sk-'开头"
elif provider == "glm":
# GLM密钥通常是较长的字符串,没有固定前缀
if len(api_key) < 10:
return False, "GLM密钥格式不正确"
elif provider == "silicon":
# 硅基流动密钥格式
if len(api_key) < 10:
return False, "硅基流动密钥格式不正确"
return True, "密钥格式正确"
def process_urls(
urls: str,
ai_provider: str,
api_key: str,
model: str,
output_dir: str,
custom_prompt: str,
progress=gr.Progress()
):
"""处理URLs的主函数"""
# 验证必填字段
if not api_key or not api_key.strip():
return "请输入API密钥", "", ""
if not model.strip():
return "请输入模型名称", "", ""
# 验证API密钥格式
is_valid, key_message = validate_api_key(api_key, ai_provider)
if not is_valid:
return f"API密钥验证失败: {key_message}", "", ""
urls_list = [url.strip() for url in urls.split('\n') if url.strip()]
if not urls_list:
return "请输入有效的URL", "", ""
# 创建输出目录
if not os.path.exists(output_dir):
os.makedirs(output_dir)
collector = ContentCollector()
ai_client = AIClient()
md_processor = MarkdownProcessor()
# 采集内容
progress(0, desc="开始采集内容...")
collected_contents = []
for i, url in enumerate(urls_list):
progress(i / len(urls_list), desc=f"采集进度 ({i+1}/{len(urls_list)})")
result = collector.extract_content(url)
collected_contents.append(result)
time.sleep(1) # 避免请求过快
# 过滤成功采集的内容
valid_contents = [c for c in collected_contents if c['success']]
if not valid_contents:
return "所有URL采集失败,请检查URL有效性", "", ""
# 合并所有内容(限制总长度)
combined_content = "\n\n".join([
f"标题: {c['title']}\n内容: {c['content'][:1000]}" # 每篇内容限制1000字符
for c in valid_contents
])
# 如果内容过长,进一步截断
if len(combined_content) > 4000:
combined_content = combined_content[:4000] + "\n\n【内容已截断】"
# AI处理
progress(0.5, desc="AI处理中...")
default_prompt = """请根据以下内容:
1. 创作一个吸引人的标题(放在开头,用# 标记)
2. 重新整合和优化内容,使其更具可读性和吸引力
3. 保持原文的核心信息
4. 使用适当的markdown格式进行排版
请直接输出处理后的markdown内容:"""
prompt = custom_prompt if custom_prompt.strip() else default_prompt
# 调用AI接口
try:
if ai_provider == "deepseek":
ai_result = ai_client.call_deepseek(combined_content, api_key.strip(), model, prompt)
elif ai_provider == "glm":
ai_result = ai_client.call_glm(combined_content, api_key.strip(), model, prompt)
elif ai_provider == "silicon":
ai_result = ai_client.call_silicon(combined_content, api_key.strip(), model, prompt)
else:
return "请选择AI提供商", "", ""
if not ai_result['success']:
error_msg = ai_result['error']
# 提供更友好的错误提示
if "timed out" in error_msg.lower():
error_msg += "\n💡 建议:请检查网络连接,或稍后重试"
elif "invalid" in error_msg.lower() or "401" in error_msg:
error_msg += "\n💡 建议:请检查API密钥是否正确且有效"
elif "429" in error_msg:
error_msg += "\n💡 建议:请求过于频繁,请等待1分钟后重试"
return f"AI处理失败: {error_msg}", "", ""
except Exception as e:
return f"AI处理异常: {str(e)}", "", ""
# 保存文件
progress(0.9, desc="保存文件中...")
# 提取标题
content_lines = ai_result['content'].split('\n')
title = "AI生成内容"
for line in content_lines:
if line.startswith('# '):
title = line[2:].strip()
break
filepath = md_processor.save_markdown(ai_result['content'], title, output_dir)
# 生成预览内容
preview_content = ai_result['content'][:500] + "..." if len(ai_result['content']) > 500 else ai_result['content']
# 生成采集结果预览
collection_preview = "采集结果:\n"
for i, content in enumerate(collected_contents, 1):
status = "✅" if content['success'] else "❌"
preview = content['content'][:100] + "..." if content['content'] else "无内容"
collection_preview += f"{i}. {status} {content['title']}\n 预览: {preview}\n"
return collection_preview, preview_content, filepath
def create_interface():
"""创建Gradio界面"""
with gr.Blocks(title="网页内容采集与AI处理系统", theme=gr.themes.Soft()) as demo:
gr.Markdown("# 🚀 网页内容采集与AI处理系统")
gr.Markdown("输入多个网址,选择AI接口,自动采集内容并重新整合为markdown格式")
with gr.Row():
with gr.Column(scale=2):
# 网址输入区域
with gr.Group():
gr.Markdown("### 📝 网址输入")
url_input = gr.Textbox(
lines=5,
placeholder="请输入网址,每行一个URL...\n例如:\nhttps://example.com/page1\nhttps://example.com/page2",
label="网址列表"
)
# AI配置区域
with gr.Group():
gr.Markdown("### 🤖 AI配置")
# 先定义模型名称和API密钥的组件
model_name = gr.Textbox(
label="模型名称",
placeholder="例如:deepseek-chat, deepseek-coder",
value="deepseek-chat",
info="对应平台的模型名称"
)
api_key = gr.Textbox(
label="API密钥",
placeholder="请输入Deepseek平台的API密钥...",
type="password",
info="从对应AI平台获取的API密钥"
)
# AI提供商放在后面定义,避免循环引用
ai_provider = gr.Dropdown(
choices=["deepseek", "glm", "silicon"],
label="AI提供商",
value="deepseek",
info="选择AI服务提供商"
)
custom_prompt = gr.Textbox(
lines=3,
label="自定义提示词",
placeholder="可选:自定义AI处理指令...",
value="""请根据以下内容:
1. 创作一个吸引人的标题(放在开头,用# 标记)
2. 重新整合和优化内容,使其更具可读性和吸引力
3. 保持原文的核心信息
4. 使用适当的markdown格式进行排版
请直接输出处理后的markdown内容:"""
)
# 输出配置
with gr.Group():
gr.Markdown("### 💾 输出配置")
output_dir = gr.Textbox(
label="保存路径",
value="./output",
placeholder="请输入保存markdown文件的目录路径"
)
# 网络诊断
with gr.Group():
gr.Markdown("### 🔧 网络诊断")
network_status = gr.Textbox(
label="网络状态",
value="点击右侧按钮检测网络",
interactive=False
)
with gr.Row():
check_network_btn = gr.Button("检测网络连接", variant="secondary")
clear_btn = gr.Button("清空所有输入", variant="secondary")
# 操作按钮
process_btn = gr.Button("🚀 开始处理", variant="primary", size="lg")
with gr.Column(scale=3):
# 结果显示区域
with gr.Group():
gr.Markdown("### 📊 处理结果")
gr.Markdown("#### 采集内容预览")
collection_preview = gr.Textbox(
lines=6,
label="采集状态和预览",
interactive=False,
show_copy_button=True
)
gr.Markdown("#### AI处理结果预览")
ai_preview = gr.Textbox(
lines=10,
label="AI生成内容预览",
interactive=False,
show_copy_button=True
)
gr.Markdown("#### 文件保存")
file_output = gr.Textbox(
label="保存路径",
interactive=False,
show_copy_button=True
)
# 绑定事件
process_btn.click(
fn=process_urls,
inputs=[url_input, ai_provider, api_key, model_name, output_dir, custom_prompt],
outputs=[collection_preview, ai_preview, file_output]
)
def perform_network_check():
success, message = check_network_connection()
icon = "✅" if success else "❌"
return f"{icon} {message}"
check_network_btn.click(
fn=perform_network_check,
outputs=network_status
)
def clear_all():
return "", "deepseek", "", "deepseek-chat", "./output", "", "", "", ""
clear_btn.click(
fn=clear_all,
outputs=[url_input, ai_provider, api_key, model_name, output_dir, custom_prompt, collection_preview, ai_preview, file_output]
)
# 示例和说明
with gr.Accordion("📖 使用说明 & 故障排除", open=False):
gr.Markdown("""
## 使用指南
1. **网址输入**:每行输入一个完整的URL地址
2. **AI配置**:
- 选择AI服务提供商(Deepseek、GLM、硅基流动)
- 输入对应的模型名称和API密钥
- 可自定义处理提示词
3. **输出配置**:设置markdown文件的保存目录
4. **开始处理**:点击按钮开始采集和处理
## 支持的AI服务配置示例
### Deepseek
- **模型名称**: `deepseek-chat`, `deepseek-coder`
- **API密钥**: 从 [Deepseek平台](https://platform.deepseek.com/) 获取
- **密钥格式**: 以 `sk-` 开头的长字符串
### GLM (智谱AI)
- **模型名称**: `glm-4`, `glm-3-turbo`
- **API密钥**: 从 [智谱AI开放平台](https://open.bigmodel.cn/) 获取
- **密钥格式**: 长字符串(不以sk-开头)
### 硅基流动
- **模型名称**: `Qwen-7B-Chat`, `Qwen-14B-Chat` 等
- **API密钥**: 从 [硅基流动平台](https://siliconflow.cn/) 获取
- **密钥格式**: 长字符串
## 常见问题解决
### ❌ 网络连接超时
- 检查网络连接是否稳定
- 尝试使用"检测网络连接"功能
- 稍后重试,可能是API服务器临时问题
### ❌ API密钥错误
- 确认密钥正确复制(注意前后空格)
- 检查密钥是否过期或被撤销
- 确认对应平台账户有足够余额
### ❌ 请求频率过高
- 等待1-2分钟后重试
- 减少单次处理的内容量
### ❌ 内容采集失败
- 检查URL是否正确且可访问
- 某些网站可能有反爬虫机制
- 尝试手动访问确认网站正常
## 注意事项
- 确保网络连接正常
- 确认API密钥有效且有足够余额
- 建议每次处理不超过10个网址
- 保存路径需要有写入权限
- 如遇问题,请查看控制台输出的详细日志
""")
return demo
def main():
"""主函数,用于打包后运行"""
try:
demo = create_interface()
print("🚀 网页内容采集与AI处理系统启动中...")
print("📍 访问地址: http://localhost:7860")
print("⏹️ 按 Ctrl+C 停止服务")
demo.launch(
server_name="0.0.0.0",
server_port=7860,
share=False,
inbrowser=True,
show_error=True
)
except Exception as e:
print(f"启动失败: {e}")
input("按回车键退出...")
if __name__ == "__main__":
main()requirements.txt
gradio>=4.0.0
requests>=2.25.0
beautifulsoup4>=4.9.0
markdown>=3.3.0
lxml>=4.6.0功能特点
- 🌐 多网址内容采集
- 🤖 支持多种AI接口 (Deepseek, GLM, 硅基流动)
- 📝 智能内容重写和标题优化
- 💾 自动保存为Markdown格式
- 🎯 可视化操作界面
- 🔄 自动重试机制
- 🔧 网络诊断功能
使用方法
-
安装依赖:
pip install -r requirements.txt -
运行程序:
python main.py -
打开浏览器访问:http://localhost:7860
需要自备API,硅基流动有很多免费模型,基本够用了:
https://cloud.siliconflow.cn/i/MeUFQmheZ